

第一印象とオンボーディング
Spice AIのウェブサイトを訪れると、すぐにクリーンで開発者向けのデザインが目に留まりました。ヒーローセクションでは「サブセカンドのクエリパフォーマンス」と「レイクハウスコストを最大80%削減」を謳っており、高いハードルを設定しています。その下には、サインアップ不要の30秒のインタラクティブウォークスルーがあり、コア機能をテストできます。これは摩擦を減らす賢い工夫です。ダッシュボードは直接表示されませんが、製品はオープンソースランタイムとマネージドクラウドプラットフォームの両方であるように見えます。「Start for free」ボタンはすぐに見つかり、クラウド層のサインアップフローに進みます。一方、OSSバージョンはローカルまたはエッジにデプロイできます。サイトには80以上のガイドを備えたクックブックがあり、出発点を見つけるのは簡単そうです。開発者向けプラットフォームとして、ドキュメントとデモへのリンクが目立つ場所に配置されており、その点は評価できます。
コア機能と技術的な深み
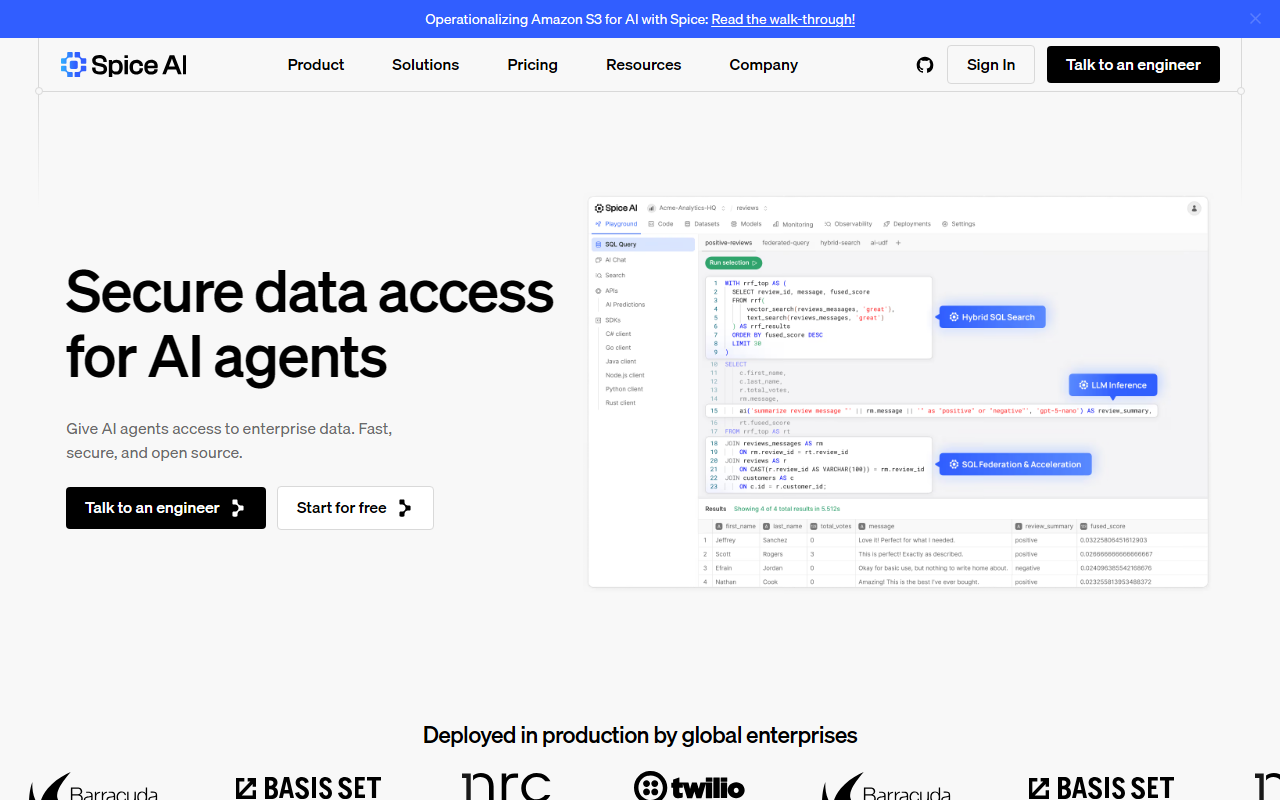
Spice AIは単なるデータパイプラインツールではなく、AIコンテキストのために特別に設計されたデータプラットフォームです。その際立った機能はSQLフェデレーションとアクセラレーションです。運用データベース、データレイク、データウェアハウスに接続し、ワーキングセットをインメモリまたはディスクに具体化して、ミリ秒単位のアクセスを実現します。サイトでは最大100倍高速なクエリを謳っていますが、インメモリアクセラレーションを考慮すると野心的ながらも妥当な数字です。もう一つの重要な機能はハイブリッド検索で、標準SQLを使用してキーワード、ベクトル、全文検索を組み合わせます。これにより、構造化フィルター、セマンティック類似性、キーワードマッチを単一のクエリでランク付けでき、グラウンディングされたコンテキスト認識結果を必要とするRAGパイプラインやAIエージェントにとって重要です。
第三の柱は組み込みAI推論です。SQL UDFまたは自然言語を使用して、クエリレイヤーから直接ホスト型またはローカルLLMを呼び出すことができます。つまり、Spiceランタイムから離れることなく、要約の生成、エンティティの分類、テキスト翻訳が可能です。内部では、Spiceは分散観測可能性を活用し、SQL、埋め込み、検索、LLM呼び出し全体にわたるエンドツーエンドトレーシングを提供します。これはデバッグやレイテンシ測定に役立ちます。また、AIサンドボックス化と最小権限データセットによるセキュリティも提供しており、RAGワークフローを有効にしながらガバナンスを維持する必要がある企業の一般的な課題に対処します。
技術的な観点から見ると、SpiceはRustで書かれた独自の軽量ランタイムを使用しているようです(オープンソースリポジトリから推測)。これにより、リソースフットプリントが低く、移植性が高い理由が説明できます。プラットフォームはローカル、エッジ、マネージドクラウドのどこにでもデプロイ可能です。価格はウェブサイトに公開されておらず、「Start for free」オプションのみがあるため、フリーミアムモデルで、スケールとサポートに対して有料層があると推測されます。この透明性の欠如は評価者をいら立たせるかもしれませんが、エンタープライズユーザーはデモをリクエストしたり、エンジニアと話したりできます。
市場でのポジショニングと代替製品
Spice AIは、従来のデータプラットフォーム(Databricks、Snowflake、ClickHouseなど)がAIワークフローに再利用されている領域に位置していますが、多くの場合、重いETLとレイテンシオーバーヘッドを伴います。Databricksがレイクハウス分析やMLトレーニングに重点を置いているのに対し、Spiceはより狭い範囲に特化しています。バッチ処理ではなく、リアルタイムAI推論とサービングに最適化されています。もう一つの競合はMindsDBで、これもSQLベースの機械学習とモデルサービングを可能にしますが、Spiceは深いフェデレーション、ハイブリッド検索、強力なオープンソース精神で差別化しています。このプラットフォームはすでにTwilio、Barracuda、NRC Healthなどの有名企業で本番運用されており、信頼性を高めています。Twilioのソフトウェアアーキテクトは、Spiceによって重要なコントロールプレーンデータセットを取得し、ランタイムパスのサービスに近接して移動できるようになったと述べています。これはレイテンシに敏感なユースケースの明確な証言です。
この製品は、データを移動せずに多様なデータソースをクエリする必要があるAIエージェント、検索駆動型アプリ、またはリアルタイムパーソナライゼーション機能を構築するチームに最適です。ベンダーロックインの回避策としてオープンソースでセルフホスト可能な代替手段を求める開発者にとって、Spiceは魅力的です。ただし、複雑なETLパイプラインや大規模なMLトレーニングを必要とする本格的なデータウェアハウスが必要な組織は、補助的なツールが必要になるかもしれません。プラットフォームがSQLフェデレーションに依存しているため、データソースがSQLでアクセス可能な場合に最適に機能します。非構造化ブロブやストリーミングイベントソースの場合は、追加のミドルウェアが必要になる可能性があります。
評価と推奨
Spice AIは、エンタープライズデータにAIを最小限のレイテンシと最大の柔軟性で基盤付けるという真の課題に対処する、革新的なプラットフォームです。その強みは、サブセカンドのクエリ速度、ソース間の統一SQL、ハイブリッド検索、組み込みLLM呼び出しであり、すべてオープンソースでポータブルなランタイムにまとめられています。インタラクティブなウォークスルーと包括的なクックブックにより、探索が容易です。制限事項は、クラウド層の価格の透明性の欠如と、バッチ処理ではなくサービングに焦点を絞っていることです。フェデレーションデータへの高速アクセスを必要とするAIアプリケーションを構築しているなら、Spiceは真剣に検討する価値があります。まずは無料層でフェデレーションとアクセラレーション機能をテストすることをお勧めします。すでにDatabricksやSnowflakeエコシステムを利用している企業の場合、Spiceはそれらのスタックを置き換えるのではなく補完することができます。Spice AIをhttps://spice.ai/でご自身で探索してください。






コメント